| Qingyuan Li | Alexandru Luchianov | ||
| Final project for MIT 6.7960 | |||

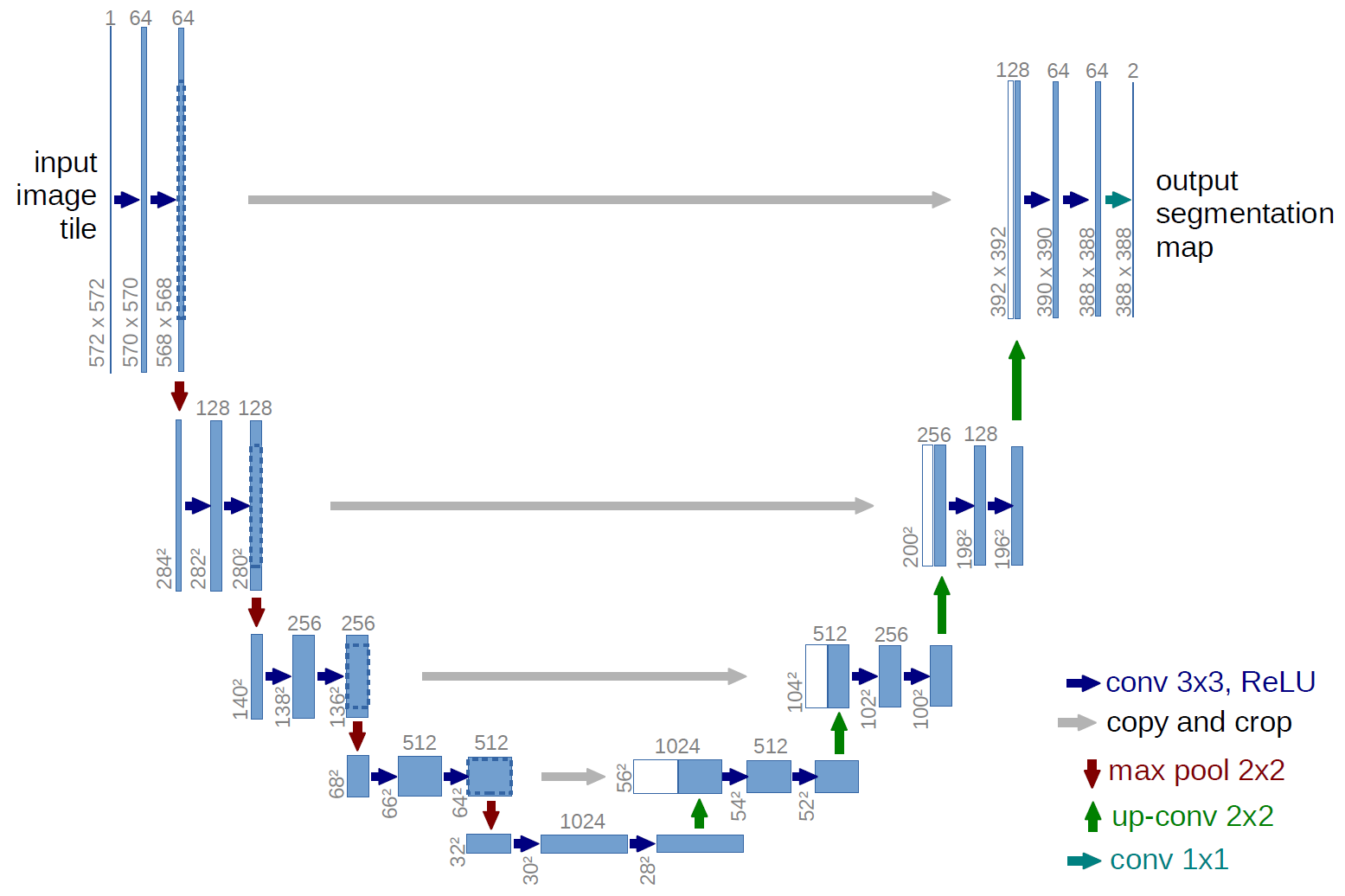
Example frame from our algorithm. Outputs from top left, clockwise: RGB image with annotated dynamic objects, depth image, raw model output mask, post-processed model output mask.
Preface
One of the previous projects of Qingyuan Li involved dynamic object tracking by using the flow residual information, however the result was lacking. This section aims to provide context as to what the previous approach did, why it failed and why deep learning is the solution.In very succinct terms, the core pipeline of the previous project could be described as such:
- Gather data for the dynamic object tracking experiment.
- Extract the optical flow from the image using a known model(RAFT)
- Process the optical flow and the original frame to obtain the objects
Video 1. Example output sequence from the evaluation dataset with the non-learned algorithm
Unfortunately, replacing the manual transformation of data by a learning model subtly (and signficantly) changes the other steps of the pipeline too. The most significant change was that of what ground truth is necessary. In the previous iteration of the project our evaluation metric was merely whether the detected location of the object was close enough to where we know the object to be. However, our segmentation model requires the whole segmentation of the object as a ground truth.
We could not collect this ground truth as we were only able to collect data about the approximate pose of the objects. Note that if we had the shape of the objects, we would have been able to generate the ground truth by simply projecting them. Our solution is to generate the ground truth using the Segment Anything model ([2]) and then train our smaller model on that. Note that training on this synthetic data makes our model inherently less accurate than SAM, however our model is much lighter.